Full version: jsB@nk » Utility » Generator » Simple Programming Language Code Syntax Highlighter with JavaScript
URL: https://www.javascriptbank.com/simple-programming-language-code-syntax-highlighter-with-javascript.html
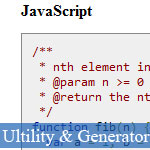 Highlighting the source codes is one very great and important functions for the website/blog that mainly shows source codes on the web pages, jsB@nk also presented you many source code syntax highlighting tools, web applications, code syntax highlighters through two JavaScript article tutorial: - Highlight your PHP and JavaScript codes with PHP highlight_string - 16 Free Code Syntax Highlighters by Javascript For Better ProgrammingReally I also had the plan to apply this cool and amazing feature to jsB@nk since two years ago, however I still could not do this intent cause of many objective reasons. But now, I'm pleasure and happy to show you new JavaScript code example for highlighting your source codes. Although it's quite simple (just compared with other highlighting tools above) but they can still work very well for all programming languages.
Highlighting the source codes is one very great and important functions for the website/blog that mainly shows source codes on the web pages, jsB@nk also presented you many source code syntax highlighting tools, web applications, code syntax highlighters through two JavaScript article tutorial: - Highlight your PHP and JavaScript codes with PHP highlight_string - 16 Free Code Syntax Highlighters by Javascript For Better ProgrammingReally I also had the plan to apply this cool and amazing feature to jsB@nk since two years ago, however I still could not do this intent cause of many objective reasons. But now, I'm pleasure and happy to show you new JavaScript code example for highlighting your source codes. Although it's quite simple (just compared with other highlighting tools above) but they can still work very well for all programming languages.
Full version: jsB@nk » Utility » Generator » Simple Programming Language Code Syntax Highlighter with JavaScript
URL: https://www.javascriptbank.com/simple-programming-language-code-syntax-highlighter-with-javascript.html
<style type="text/css">/* This script downloaded from www.JavaScriptBank.com Come to view and download over 2000+ free javascript at www.JavaScriptBank.com*//* Pretty printing styles. */.str { color: #080; }.kwd { color: #008; }.com { color: #800; }.typ { color: #606; }.lit { color: #066; }.pun { color: #660; }.pln { color: #000; }.tag { color: #008; }.atn { color: #606; }.atv { color: #080; }.dec { color: #606; }pre.prettyprint { padding: 10px; border: 1px solid #888; text-align: left;}@media print { .str { color: #060; } .kwd { color: #006; font-weight: bold; } .com { color: #600; font-style: italic; } .typ { color: #404; font-weight: bold; } .lit { color: #044; } .pun { color: #440; } .pln { color: #000; } .tag { color: #006; font-weight: bold; } .atn { color: #404; } .atv { color: #060; }}</style><script type="text/javascript">// Created by: Mike Samuel | http://code.google.com/p/google-code-prettify/// This script downloaded from www.JavaScriptBank.com/* Copyright (C) 2006 Google Inc.Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.Use these codes to determine the display colors:id="bash"id="C"id="Cpp"id="java"id="issue12"id="python"id="xml"id="htmlXmp"id="xhtml"id="PHP"id="xsl"id="whitespace"Example:<pre class="prettyprint" id="javascript">... code ...</pre><code class="prettyprint" id="javascript">... code ...</code>*/// ===========================================================var PR_keywords = {};/** initialize the keyword list for our target languages. */(function () { var CPP_KEYWORDS = "abstract bool break case catch char class const " + "const_cast continue default delete deprecated dllexport dllimport do " + "double dynamic_cast else enum explicit extern false float for friend " + "goto if inline int long mutable naked namespace new noinline noreturn " + "nothrow novtable operator private property protected public register " + "reinterpret_cast return selectany short signed sizeof static " + "static_cast struct switch template this thread throw true try typedef " + "typeid typename union unsigned using declaration, directive uuid " + "virtual void volatile while typeof"; var CSHARP_KEYWORDS = "as base by byte checked decimal delegate descending " + "event finally fixed foreach from group implicit in interface internal " + "into is lock null object out override orderby params readonly ref sbyte " + "sealed stackalloc string select uint ulong unchecked unsafe ushort var"; var JAVA_KEYWORDS = "package synchronized boolean implements import throws " + "instanceof transient extends final strictfp native super"; var JSCRIPT_KEYWORDS = "debugger export function with NaN Infinity"; var PERL_KEYWORDS = "require sub unless until use elsif BEGIN END"; var PYTHON_KEYWORDS = "and assert def del elif except exec global lambda " + "not or pass print raise yield False True None"; var RUBY_KEYWORDS = "then end begin rescue ensure module when undef next " + "redo retry alias defined"; var SH_KEYWORDS = "done fi"; var KEYWORDS = [CPP_KEYWORDS, CSHARP_KEYWORDS, JAVA_KEYWORDS, JSCRIPT_KEYWORDS, PERL_KEYWORDS, PYTHON_KEYWORDS, RUBY_KEYWORDS, SH_KEYWORDS]; for (var k = 0; k < KEYWORDS.length; k++) { var kw = KEYWORDS[k].split(' '); for (var i = 0; i < kw.length; i++) { if (kw[i]) { PR_keywords[kw[i]] = true; } } }}).call(this);// token style names. correspond to css classes/** token style for a string literal */var PR_STRING = 'str';/** token style for a keyword */var PR_KEYWORD = 'kwd';/** token style for a comment */var PR_COMMENT = 'com';/** token style for a type */var PR_TYPE = 'typ';/** token style for a literal value. e.g. 1, null, true. */var PR_LITERAL = 'lit';/** token style for a punctuation string. */var PR_PUNCTUATION = 'pun';/** token style for a punctuation string. */var PR_PLAIN = 'pln';/** token style for an sgml tag. */var PR_TAG = 'tag';/** token style for a markup declaration such as a DOCTYPE. */var PR_DECLARATION = 'dec';/** token style for embedded source. */var PR_SOURCE = 'src';/** token style for an sgml attribute name. */var PR_ATTRIB_NAME = 'atn';/** token style for an sgml attribute value. */var PR_ATTRIB_VALUE = 'atv';/** the number of characters between tab columns */var PR_TAB_WIDTH = 8;// some string utilitiesfunction PR_isWordChar(ch) { return (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z');}/** Splice one array into another. * Like the python <code> * container[containerPosition:containerPosition + countReplaced] = inserted * </code> * @param {Array} inserted * @param {Array} container modified in place * @param {Number} containerPosition * @param {Number} countReplaced */function PR_spliceArrayInto( inserted, container, containerPosition, countReplaced) { inserted.unshift(containerPosition, countReplaced || 0); try { container.splice.apply(container, inserted); } finally { inserted.splice(0, 2); }}/** a set of tokens that can precede a regular expression literal in javascript. * http://www.mozilla.org/js/language/js20/rationale/syntax.html has the full * list, but I've removed ones that might be problematic when seen in languages * that don't support regular expression literals. * * <p>Specifically, I've removed any keywords that can't precede a regexp * literal in a syntactically legal javascript program, and I've removed the * "in" keyword since it's not a keyword in many languages, and might be used * as a count of inches. * @private */var REGEXP_PRECEDER_PATTERN = (function () { var preceders = [ "!", "!=", "!==", "#", "%", "%=", "&", "&&", "&&=", "&=", "(", "*", "*=", /* "+", */ "+=", ",", /* "-", */ "-=", "->", /*".", "..", "...", handled below */ "/", "/=", ":", "::", ";", "<", "<<", "<<=", "<=", "=", "==", "===", ">", ">=", ">>", ">>=", ">>>", ">>>=", "?", "@", "[", "^", "^=", "^^", "^^=", "{", "|", "|=", "||", "||=", "~", "break", "case", "continue", "delete", "do", "else", "finally", "instanceof", "return", "throw", "try", "typeof" ]; var pattern = '(?:' + '(?:(?:^|[^0-9\.])\\.{1,3})|' + // a dot that's not part of a number '(?:(?:^|[^\\+])\\+)|' + // allow + but not ++ '(?:(?:^|[^\\-])-)' // allow - but not -- ; for (var i = 0; i < preceders.length; ++i) { var preceder = preceders[i]; if (PR_isWordChar(preceder.charAt(0))) { pattern += '|\\b' + preceder; } else { pattern += '|' + preceder.replace(/([^=<>:&])/g, '\\$1'); } } pattern += '|^)\\s*$'; // matches at end, and matches empty string return new RegExp(pattern); // CAVEAT: this does not properly handle the case where a regular expression // immediately follows another since a regular expression may have flags // for case-sensitivity and the like. Having regexp tokens adjacent is not // valid in any language I'm aware of, so I'm punting. // TODO: maybe style special characters inside a regexp as punctuation. })();// Define regexps here so that the interpreter doesn't have to create an object// each time the function containing them is called.// The language spec requires a new object created even if you don't access the// $1 members.var pr_amp = /&/g;var pr_lt = /</g;var pr_gt = />/g;var pr_quot = /\"/g;/** like textToHtml but escapes double quotes to be attribute safe. */function PR_attribToHtml(str) { return str.replace(pr_amp, '&') .replace(pr_lt, '<') .replace(pr_gt, '>') .replace(pr_quot, '"');}/** escapest html special characters to html. */function PR_textToHtml(str) { return str.replace(pr_amp, '&') .replace(pr_lt, '<') .replace(pr_gt, '>');}var pr_ltEnt = /</g;var pr_gtEnt = />/g;var pr_aposEnt = /'/g;var pr_quotEnt = /"/g;var pr_ampEnt = /&/g;/** unescapes html to plain text. */function PR_htmlToText(html) { var pos = html.indexOf('&'); if (pos < 0) { return html; } // Handle numeric entities specially. We can't use functional substitution // since that doesn't work in older versions of Safari. // These should be rare since most browsers convert them to normal chars. for (--pos; (pos = html.indexOf('&#', pos + 1)) >= 0;) { var end = html.indexOf(';', pos); if (end >= 0) { var num = html.substring(pos + 3, end); var radix = 10; if (num && num.charAt(0) == 'x') { num = num.substring(1); radix = 16; } var codePoint = parseInt(num, radix); if (!isNaN(codePoint)) { html = (html.substring(0, pos) + String.fromCharCode(codePoint) + html.substring(end + 1)); } } } return html.replace(pr_ltEnt, '<') .replace(pr_gtEnt, '>') .replace(pr_aposEnt, "'") .replace(pr_quotEnt, '"') .replace(pr_ampEnt, '&');}/** is the given node's innerHTML normally unescaped? */function PR_isRawContent(node) { return 'XMP' == node.tagName;}var PR_innerHtmlWorks = null;function PR_getInnerHtml(node) { // inner html is hopelessly broken in Safari 2.0.4 when the content is // an html description of well formed XML and the containing tag is a PRE // tag, so we detect that case and emulate innerHTML. if (null === PR_innerHtmlWorks) { var testNode = document.createElement('PRE'); testNode.appendChild( document.createTextNode('<!DOCTYPE foo PUBLIC "foo bar">\n<foo />')); PR_innerHtmlWorks = !/</.test(testNode.innerHTML); } if (PR_innerHtmlWorks) { var content = node.innerHTML; // XMP tags contain unescaped entities so require special handling. if (PR_isRawContent(node)) { content = PR_textToHtml(content); } return content; } var out = []; for (var child = node.firstChild; child; child = child.nextSibling) { PR_normalizedHtml(child, out); } return out.join('');}/** walks the DOM returning a properly escaped version of innerHTML. */function PR_normalizedHtml(node, out) { switch (node.nodeType) { case 1: // an element var name = node.tagName.toLowerCase(); out.push('\074', name); for (var i = 0; i < node.attributes.length; ++i) { var attr = node.attributes[i]; if (!attr.specified) { continue; } out.push(' '); PR_normalizedHtml(attr, out); } out.push('>'); for (var child = node.firstChild; child; child = child.nextSibling) { PR_normalizedHtml(child, out); } if (node.firstChild || !/^(?:br|link|img)$/.test(name)) { out.push('<\/', name, '>'); } break; case 2: // an attribute out.push(node.name.toLowerCase(), '="', PR_attribToHtml(node.value), '"'); break; case 3: case 4: // text out.push(PR_textToHtml(node.nodeValue)); break; }}/** returns a function that expand tabs to spaces. This function can be fed * successive chunks of text, and will maintain its own internal state to * keep track of how tabs are expanded. * @return {function (plainText : String) : String } a function that takes * plain text and return the text with tabs expanded. * @private */function PR_tabExpander(tabWidth) { var SPACES = ' '; var charInLine = 0; return function (plainText) { // walk over each character looking for tabs and newlines. // On tabs, expand them. On newlines, reset charInLine. // Otherwise increment charInLine var out = null; var pos = 0; for (var i = 0, n = plainText.length; i < n; ++i) { var ch = plainText.charAt(i); switch (ch) { case '\t': if (!out) { out = []; } out.push(plainText.substring(pos, i)); // calculate how much space we need in front of this part // nSpaces is the amount of padding -- the number of spaces needed to // move us to the next column, where columns occur at factors of // tabWidth. var nSpaces = tabWidth - (charInLine % tabWidth); charInLine += nSpaces; for (; nSpaces >= 0; nSpaces -= SPACES.length) { out.push(SPACES.substring(0, nSpaces)); } pos = i + 1; break; case '\n': charInLine = 0; break; default: ++charInLine; } } if (!out) { return plainText; } out.push(plainText.substring(pos)); return out.join(''); };}// The below pattern matches one of the following// (1) /[^<]+/ : A run of characters other than '<'// (2) /<!--.*?-->/: an HTML comment// (3) /<!\[CDATA\[.*?\]\]>/: a cdata section// (3) /<\/?[a-zA-Z][^>]*>/ : A probably tag that should not be highlighted// (4) /</ : A '<' that does not begin a larger chunk. Treated as 1var pr_chunkPattern = /(?:[^<]+|<!--[\s\S]*?-->|<!\[CDATA\[([\s\S]*?)\]\]>|<\/?[a-zA-Z][^>]*>|<)/g;var pr_commentPrefix = /^<!--/;var pr_cdataPrefix = /^<\[CDATA\[/;var pr_brPrefix = /^<br\b/i;/** split markup into chunks of html tags (style null) and * plain text (style {@link #PR_PLAIN}), converting tags which are significant * for tokenization (<br>) into their textual equivalent. * * @param {String} s html where whitespace is considered significant. * @return {Object} source code and extracted tags. * @private */function PR_extractTags(s) { // since the pattern has the 'g' modifier and defines no capturing groups, // this will return a list of all chunks which we then classify and wrap as // PR_Tokens var matches = s.match(pr_chunkPattern); var sourceBuf = []; var sourceBufLen = 0; var extractedTags = []; if (matches) { for (var i = 0, n = matches.length; i < n; ++i) { var match = matches[i]; if (match.length > 1 && match.charAt(0) === '<') { if (pr_commentPrefix.test(match)) { continue; } if (pr_cdataPrefix.test(match)) { // strip CDATA prefix and suffix. Don't unescape since it's CDATA sourceBuf.push(match.substring(9, match.length - 3)); sourceBufLen += match.length - 12; } else if (pr_brPrefix.test(match)) { // <br> tags are lexically significant so convert them to text. // This is undone later. // <br> tags are lexically significant sourceBuf.push('\n'); sourceBufLen += 1; } else { extractedTags.push(sourceBufLen, match); } } else { var literalText = PR_htmlToText(match); sourceBuf.push(literalText); sourceBufLen += literalText.length; } } } return { source: sourceBuf.join(''), tags: extractedTags };}/** Given triples of [style, pattern, context] returns a lexing function, * The lexing function interprets the patterns to find token boundaries and * returns a decoration list of the form * [index_0, style_0, index_1, style_1, ..., index_n, style_n] * where index_n is an index into the sourceCode, and style_n is a style * constant like PR_PLAIN. index_n-1 <= index_n, and style_n-1 applies to * all characters in sourceCode[index_n-1:index_n]. * * The stylePatterns is a list whose elements have the form * [style : String, pattern : RegExp, context : RegExp, shortcut : String]. & * Style is a style constant like PR_PLAIN. * * Pattern must only match prefixes, and if it matches a prefix and context is * null or matches the last non-comment token parsed, then that match is * considered a token with the same style. * * Context is applied to the last non-whitespace, non-comment token recognized. * * Shortcut is an optional string of characters, any of which, if the first * character, gurantee that this pattern and only this pattern matches. * * @param {Array} shortcutStylePatterns patterns that always start with * a known character. Must have a shortcut string. * @param {Array} fallthroughStylePatterns patterns that will be tried in order * if the shortcut ones fail. May have shortcuts. * * @return {function (sourceCode : String) -> Array.<Number|String>} a function * that takes source code and a list of decorations to append to. */function PR_createSimpleLexer(shortcutStylePatterns, fallthroughStylePatterns) { var shortcuts = {}; (function () { var allPatterns = shortcutStylePatterns.concat(fallthroughStylePatterns); for (var i = allPatterns.length; --i >= 0;) { var patternParts = allPatterns[i]; var shortcutChars = patternParts[3]; if (shortcutChars) { for (var c = shortcutChars.length; --c >= 0;) { shortcuts[shortcutChars.charAt(c)] = patternParts; } } } })(); var nPatterns = fallthroughStylePatterns.length; return function (sourceCode, opt_basePos) { opt_basePos = opt_basePos || 0; var decorations = [opt_basePos, PR_PLAIN]; var lastToken = ''; var pos = 0; // index into sourceCode var tail = sourceCode; while (tail.length) { var style; var token = null; var patternParts = shortcuts[tail.charAt(0)]; if (patternParts) { var match = tail.match(patternParts[1]); token = match[0]; style = patternParts[0]; } else { for (var i = 0; i < nPatterns; ++i) { patternParts = fallthroughStylePatterns[i]; var contextPattern = patternParts[2]; if (contextPattern && !contextPattern.test(lastToken)) { // rule can't be used continue; } var match = tail.match(patternParts[1]); if (match) { token = match[0]; style = patternParts[0]; break; } } if (!token) { // make sure that we make progress style = PR_PLAIN; token = tail.substring(0, 1); } } decorations.push(opt_basePos + pos, style); pos += token.length; tail = tail.substring(token.length); if (style !== PR_COMMENT && /\S/.test(token)) { lastToken = token; } } return decorations; };}var PR_C_STYLE_STRING_AND_COMMENT_LEXER = PR_createSimpleLexer([ [PR_STRING, /^\'(?:[^\\\']|\\[\s\S])*(?:\'|$)/, null, "'"], [PR_STRING, /^\"(?:[^\\\"]|\\[\s\S])*(?:\"|$)/, null, '"'], [PR_STRING, /^\`(?:[^\\\`]|\\[\s\S])*(?:\`|$)/, null, '`'] ], [ [PR_PLAIN, /^(?:[^\'\"\`\/\#]+)/, null, ' \r\n'], [PR_COMMENT, /^#[^\r\n]*/, null, '#'], [PR_COMMENT, /^\/\/[^\r\n]*/, null], [PR_STRING, /^\/(?:[^\\\*\/]|\\[\s\S])+(?:\/|$)/, REGEXP_PRECEDER_PATTERN], [PR_COMMENT, /^\/\*[\s\S]*?(?:\*\/|$)/, null] ]);/** splits the given string into comment, string, and "other" tokens. * @param {String} sourceCode as plain text * @return {Array.<Number|String>} a decoration list. * @private */function PR_splitStringAndCommentTokens(sourceCode) { return PR_C_STYLE_STRING_AND_COMMENT_LEXER(sourceCode);}var PR_C_STYLE_LITERAL_IDENTIFIER_PUNC_RECOGNIZER = PR_createSimpleLexer([], [ [PR_PLAIN, /^\s+/, null, ' \r\n'], // TODO(mikesamuel): recognize non-latin letters and numerals in identifiers [PR_PLAIN, /^[a-z_$@][a-z_$@0-9]*/i, null], // A hex number [PR_LITERAL, /^0x[a-f0-9]+[a-z]/i, null], // An octal or decimal number, possibly in scientific notation [PR_LITERAL, /^(?:\d(?:_\d+)*\d*(?:\.\d*)?|\.\d+)(?:e[+-]?\d+)?[a-z]*/i, null, '123456789'], [PR_PUNCTUATION, /^[^\s\w\.$@]+/, null] // Fallback will handle decimal points not adjacent to a digit ]);/** splits plain text tokens into more specific tokens, and then tries to * recognize keywords, and types. * @private */function PR_splitNonStringNonCommentTokens(source, decorations) { for (var i = 0; i < decorations.length; i += 2) { var style = decorations[i + 1]; if (style === PR_PLAIN) { var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; var chunk = source.substring(start, end); var subDecs = PR_C_STYLE_LITERAL_IDENTIFIER_PUNC_RECOGNIZER(chunk, start); for (var j = 0, m = subDecs.length; j < m; j += 2) { var subStyle = subDecs[j + 1]; if (subStyle === PR_PLAIN) { var subStart = subDecs[j]; var subEnd = j + 2 < m ? subDecs[j + 2] : chunk.length; var token = source.substring(subStart, subEnd); if (token == '.') { subDecs[j + 1] = PR_PUNCTUATION; } else if (token in PR_keywords) { subDecs[j + 1] = PR_KEYWORD; } else if (/^@?[A-Z][A-Z$]*[a-z][A-Za-z$]*$/.test(token)) { // classify types and annotations using Java's style conventions subDecs[j + 1] = token.charAt(0) == '@' ? PR_LITERAL : PR_TYPE; } } } PR_spliceArrayInto(subDecs, decorations, i, 2); i += subDecs.length - 2; } } return decorations;}var PR_MARKUP_LEXER = PR_createSimpleLexer([], [ [PR_PLAIN, /^[^<]+/, null], [PR_DECLARATION, /^<!\w[^>]*(?:>|$)/, null], [PR_COMMENT, /^<!--[\s\S]*?(?:-->|$)/, null], [PR_SOURCE, /^<\?[\s\S]*?(?:\?>|$)/, null], [PR_SOURCE, /^<%[\s\S]*?(?:%>|$)/, null], [PR_SOURCE, // Tags whose content is not escaped, and which contain source code. /^<(script|style|xmp)\b[^>]*>[\s\S]*?<\/\1\b[^>]*>/i, null], [PR_TAG, /^<\/?\w[^<>]*>/, null] ]);// Splits any of the source|style|xmp entries above into a start tag,// source content, and end tag.var PR_SOURCE_CHUNK_PARTS = /^(<[^>]*>)([\s\S]*)(<\/[^>]*>)$/;/** split markup on tags, comments, application directives, and other top level * constructs. Tags are returned as a single token - attributes are not yet * broken out. * @private */function PR_tokenizeMarkup(source) { var decorations = PR_MARKUP_LEXER(source); for (var i = 0; i < decorations.length; i += 2) { if (decorations[i + 1] === PR_SOURCE) { var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; // Split out start and end script tags as actual tags, and leave the body // with style SCRIPT. var sourceChunk = source.substring(start, end); var match = (sourceChunk.match(PR_SOURCE_CHUNK_PARTS) //|| sourceChunk.match(/^(<[?%])([\s\S]*)([?%]>)$/) ); if (match) { decorations.splice( i, 2, start, PR_TAG, // the open chunk start + match[1].length, PR_SOURCE, start + match[1].length + (match[2] || '').length, PR_TAG); } } } return decorations;}var PR_TAG_LEXER = PR_createSimpleLexer([ [PR_ATTRIB_VALUE, /^\'[^\']*(?:\'|$)/, null, "'"], [PR_ATTRIB_VALUE, /^\"[^\"]*(?:\"|$)/, null, '"'], [PR_PUNCTUATION, /^[<>\/=]+/, null, '<>/='] ], [ [PR_TAG, /^[\w-]+/, /^</], [PR_ATTRIB_VALUE, /^[\w-]+/, /^=/], [PR_ATTRIB_NAME, /^[\w-]+/, null], [PR_PLAIN, /^\s+/, null, ' \r\n'] ]);/** split tags attributes and their values out from the tag name, and * recursively lex source chunks. * @private */function PR_splitTagAttributes(source, decorations) { for (var i = 0; i < decorations.length; i += 2) { var style = decorations[i + 1]; if (style === PR_TAG) { var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; var chunk = source.substring(start, end); var subDecorations = PR_TAG_LEXER(chunk, start); PR_spliceArrayInto(subDecorations, decorations, i, 2); i += subDecorations.length - 2; } } return decorations;}/** identify regions of markup that are really source code, and recursivley * lex them. * @private */function PR_splitSourceNodes(source, decorations) { for (var i = 0; i < decorations.length; i += 2) { var style = decorations[i + 1]; if (style == PR_SOURCE) { // Recurse using the non-markup lexer var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; var subDecorations = PR_decorateSource(source.substring(start, end)); for (var j = 0, m = subDecorations.length; j < m; j += 2) { subDecorations[j] += start; } PR_spliceArrayInto(subDecorations, decorations, i, 2); i += subDecorations.length - 2; } } return decorations;}/** identify attribute values that really contain source code and recursively * lex them. * @private */function PR_splitSourceAttributes(source, decorations) { var nextValueIsSource = false; for (var i = 0; i < decorations.length; i += 2) { var style = decorations[i + 1]; if (style === PR_ATTRIB_NAME) { var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; nextValueIsSource = /^on|^style$/i.test(source.substring(start, end)); } else if (style == PR_ATTRIB_VALUE) { if (nextValueIsSource) { var start = decorations[i]; var end = i + 2 < decorations.length ? decorations[i + 2] : source.length; var attribValue = source.substring(start, end); var attribLen = attribValue.length; var quoted = (attribLen >= 2 && /^[\"\']/.test(attribValue) && attribValue.charAt(0) === attribValue.charAt(attribLen - 1)); var attribSource; var attribSourceStart; var attribSourceEnd; if (quoted) { attribSourceStart = start + 1; attribSourceEnd = end - 1; attribSource = attribValue; } else { attribSourceStart = start + 1; attribSourceEnd = end - 1; attribSource = attribValue.substring(1, attribValue.length - 1); } var attribSourceDecorations = PR_decorateSource(attribSource); for (var j = 0, m = attribSourceDecorations.length; j < m; j += 2) { attribSourceDecorations[j] += attribSourceStart; } if (quoted) { attribSourceDecorations.push(attribSourceEnd, PR_ATTRIB_VALUE); PR_spliceArrayInto(attribSourceDecorations, decorations, i + 2, 0); } else { PR_spliceArrayInto(attribSourceDecorations, decorations, i, 2); } } nextValueIsSource = false; } } return decorations;}/** returns a list of decorations, where even entries * * This code treats ", ', and ` as string delimiters, and \ as a string escape. * It does not recognize perl's qq() style strings. It has no special handling * for double delimiter escapes as in basic, or tje tripled delimiters used in * python, but should work on those regardless although in those cases a single * string literal may be broken up into multiple adjacent string literals. * * It recognizes C, C++, and shell style comments. * * @param {String} sourceCode as plain text * @return {Array.<String,Number>} a decoration list */function PR_decorateSource(sourceCode) { // Split into strings, comments, and other. // We do this because strings and comments are easily recognizable and can // contain stuff that looks like other tokens, so we want to mark those early // so we don't recurse into them. var decorations = PR_splitStringAndCommentTokens(sourceCode); // Split non comment|string tokens on whitespace and word boundaries decorations = PR_splitNonStringNonCommentTokens(sourceCode, decorations); return decorations;}/** returns a decoration list given a string of markup. * * This code recognizes a number of constructs. * <!-- ... --> comment * <!\w ... > declaration * <\w ... > tag * </\w ... > tag * < ?...?> embedded source * <%...%> embedded source * &[#\w]...; entity * * It does not recognizes %foo; doctype entities from . * * It will recurse into any <style>, <script>, and on* attributes using * PR_lexSource. */function PR_decorateMarkup(sourceCode) { // This function works as follows: // 1) Start by splitting the markup into text and tag chunks // Input: String s // Output: List<PR_Token> where style in (PR_PLAIN, null) // 2) Then split the text chunks further into comments, declarations, // tags, etc. // After each split, consider whether the token is the start of an // embedded source section, i.e. is an open <script> tag. If it is, // find the corresponding close token, and don't bother to lex in between. // Input: List<String> // Output: List<PR_Token> with style in (PR_TAG, PR_PLAIN, PR_SOURCE, null) // 3) Finally go over each tag token and split out attribute names and values. // Input: List<PR_Token> // Output: List<PR_Token> where style in // (PR_TAG, PR_PLAIN, PR_SOURCE, NAME, VALUE, null) var decorations = PR_tokenizeMarkup(sourceCode); decorations = PR_splitTagAttributes(sourceCode, decorations); decorations = PR_splitSourceNodes(sourceCode, decorations); decorations = PR_splitSourceAttributes(sourceCode, decorations); return decorations;}/** * @param {String} sourceText plain text * @param {Array.<Number|String>} extractedTags chunks of raw html preceded by * their position in sourceText in order. * @param {Array.<Number|String> decorations style classes preceded by their * position in sourceText in order. * @return {String} html * @private */function PR_recombineTagsAndDecorations( sourceText, extractedTags, decorations) { var html = []; var outputIdx = 0; // index past the last char in sourceText written to html var openDecoration = null; var currentDecoration = null; var tagPos = 0; // index into extractedTags var decPos = 0; // index into decorations var tabExpander = PR_tabExpander(PR_TAB_WIDTH); // A helper function that is responsible for opening sections of decoration // and outputing properly escaped chunks of source function emitTextUpTo(sourceIdx) { if (sourceIdx > outputIdx) { if (openDecoration && openDecoration !== currentDecoration) { // Close the current decoration html.push('</span>'); openDecoration = null; } if (!openDecoration && currentDecoration) { openDecoration = currentDecoration; html.push('<span class="', openDecoration, '">'); } // This interacts badly with some wikis which introduces paragraph tags // into pre blocks for some strange reason. // It's necessary for IE though which seems to lose the preformattednes // of <pre> tags when their innerHTML is assigned. // http://stud3.tuwien.ac.at/~e0226430/innerHtmlQuirk.html // and it serves to undo the conversion of <br>s to newlines done in // chunkify. var htmlChunk = PR_textToHtml( tabExpander(sourceText.substring(outputIdx, sourceIdx))) .replace(/(\r\n?|\n| ) /g, '$1 ') .replace(/\r\n?|\n/g, '<br>'); html.push(htmlChunk); outputIdx = sourceIdx; } } while (true) { // Determine if we're going to consume a tag this time around. Otherwise we // consume a decoration or exit. var outputTag; if (tagPos < extractedTags.length) { if (decPos < decorations.length) { // Pick one giving preference to extractedTags since we shouldn't open // a new style that we're going to have to immediately close in order // to output a tag. outputTag = extractedTags[tagPos] <= decorations[decPos]; } else { outputTag = true; } } else { outputTag = false; } // Consume either a decoration or a tag or exit. if (outputTag) { emitTextUpTo(extractedTags[tagPos]); if (openDecoration) { // Close the current decoration html.push('</span>'); openDecoration = null; } html.push(extractedTags[tagPos + 1]); tagPos += 2; } else if (decPos < decorations.length) { emitTextUpTo(decorations[decPos]); currentDecoration = decorations[decPos + 1]; decPos += 2; } else { break; } } emitTextUpTo(sourceText.length); if (openDecoration) { html.push('</span>'); } return html.join('');}/** pretty print a chunk of code. * * @param {String} sourceCodeHtml code as html * @return {String} code as html, but prettier */function prettyPrintOne(sourceCodeHtml) { try { // Extract tags, and convert the source code to plain text. var sourceAndExtractedTags = PR_extractTags(sourceCodeHtml); /** Plain text. @type {String} */ var source = sourceAndExtractedTags.source; /** Even entries are positions in source in ascending order. Odd entries * are tags that were extracted at that position. * @type {Array.<Number|String>} */ var extractedTags = sourceAndExtractedTags.tags; // Pick a lexer and apply it. /** Treat it as markup if the first non whitespace character is a < and the * last non-whitespace character is a >. * @type {Boolean} */ var isMarkup = /^\s*</.test(source) && />\s*$/.test(source); /** Even entires are positions in source in ascending order. Odd enties are * style markers (e.g., PR_COMMENT) that run from that position until the * end. * @type {Array.<Number|String>} */ var decorations = isMarkup ? PR_decorateMarkup(source) : PR_decorateSource(source); // Integrate the decorations and tags back into the source code to produce // a decorated html string. return PR_recombineTagsAndDecorations(source, extractedTags, decorations); } catch (e) { if ('console' in window) { console.log(e); console.trace(); } return sourceCodeHtml; }}var PR_SHOULD_USE_CONTINUATION = true;/** find all the < pre > and < code > tags in the DOM with class=prettyprint and * prettify them. * @param {Function} opt_whenDone if specified, called when the last entry * has been finished. */function prettyPrint(opt_whenDone) { // fetch a list of nodes to rewrite var codeSegments = [ document.getElementsByTagName('pre'), document.getElementsByTagName('code'), document.getElementsByTagName('xmp') ]; var elements = []; for (var i = 0; i < codeSegments.length; ++i) { for (var j = 0; j < codeSegments[i].length; ++j) { elements.push(codeSegments[i][j]); } } codeSegments = null; // the loop is broken into a series of continuations to make sure that we // don't make the browser unresponsive when rewriting a large page. var k = 0; function doWork() { var endTime = (PR_SHOULD_USE_CONTINUATION ? new Date().getTime() + 250 : Infinity); for (; k < elements.length && new Date().getTime() < endTime; k++) { var cs = elements[k]; if (cs.className && cs.className.indexOf('prettyprint') >= 0) { // make sure this is not nested in an already prettified element var nested = false; for (var p = cs.parentNode; p != null; p = p.parentNode) { if ((p.tagName == 'pre' || p.tagName == 'code' || p.tagName == 'xmp') && p.className && p.className.indexOf('prettyprint') >= 0) { nested = true; break; } } if (!nested) { // fetch the content as a snippet of properly escaped HTML. // Firefox adds newlines at the end. var content = PR_getInnerHtml(cs); content = content.replace(/(?:\r\n?|\n)$/, ''); // do the pretty printing var newContent = prettyPrintOne(content); // push the prettified html back into the tag. if (!PR_isRawContent(cs)) { // just replace the old html with the new cs.innerHTML = newContent; } else { // we need to change the tag to a <pre> since <xmp>s do not allow // embedded tags such as the span tags used to attach styles to // sections of source code. var pre = document.createElement('PRE'); for (var i = 0; i < cs.attributes.length; ++i) { var a = cs.attributes[i]; if (a.specified) { pre.setAttribute(a.name, a.value); } } pre.innerHTML = newContent; // remove the old cs.parentNode.replaceChild(pre, cs); } } } } if (k < elements.length) { // finish up in a continuation setTimeout(doWork, 250); } else if (opt_whenDone) { opt_whenDone(); } } doWork();}</script><div style="width: 400px; margin-left: 10%"><strong>JavaScript</strong><br><pre class="prettyprint" id="javascript">/** * nth element in the fibonacci series. * @param n >= 0 * @return the nth element, >= 0. */function fib(n) { var a = 1, b = 1; var tmp; while (--n >= 0) { tmp = a; a += b; b = tmp; } return a;}document.write(fib(10));</pre><strong>PHP</strong><br><pre class="prettyprint" id="php"><html> <head> <title><?= 'Fibonacci numbers' ?></title> <?php // PHP has a plethora of comment types /* What is a "plethora"? */ function fib($n) { # I don't know. $a = 1; $b = 1; while (--$n >= 0) { echo "$a\n"; $tmp = $a; $a += $b; $b = $tmp; } } ?> </head> <body> <?= fib(10) ?> </body></html></pre><strong>HTML</strong><br><pre class="prettyprint" id="javascript"><html> <head> <title>Fibonacci number</title> </head> <body> <noscript> <dl> <dt>Fibonacci numbers</dt> <dd>1</dd> <dd>1</dd> <dd>2</dd> <dd>3</dd> <dd>5</dd> <dd>8</dd> … </dl> </noscript> <script type="text/javascript"><!--function fib(n) { var a = 1, b = 1; var tmp; while (--n >= 0) { tmp = a; a += b; b = tmp; } return a;}document.writeln(fib(10));// --> </script> </body></html></pre></div><strong>In Sentences</strong><br><p>Lorem ipsum dolor sit amet, <code class="prettyprint" id="html"><script type="text/javascript"></code> consectetuer adipiscing elit. Ma quande <code class="prettyprint" id="javascript">function lingues()</code> coalesce, li grammatica del resultant.</p></p></div><script type="text/javascript">// Multiple onload function created by: Simon Willison// http://simonwillison.net/2004/May/26/addLoadEvent/function addLoadEvent(func) { var oldonload = window.onload; if (typeof window.onload != 'function') { window.onload = func; } else { window.onload = function() { if (oldonload) { oldonload(); } func(); } }}addLoadEvent(function() { prettyPrint();});</script> 